Skip to content
- 데이터베이스 물리 속성 설계
- 파티셔닝 : 큰 테이블이나 인덱스를 관리하기 쉬운 단위로 분리하는 방법
- 장점
- 가용성 : 물리적인 파티셔닝으로 인해 전체 데이터의 훼손 가능성이 줄어들고 데이터 가용성이 향상
- 관리용이성 : 큰 테이블을 제거하여 관리를 쉽게 함
- 성능 : DML과 Query의 성능을 향상시킴
- 단점
- 테이블간 Join에 대한 비용 증가
- 테이블과 인덱스를 별도로 파티션할 수 없다. 즉, 같이해야 한다
- 범위
- Range 파티셔닝 : 연속적인 숫자, 날짜 기준
- 우편번호, 일별, 월별, 분기별 등에 적합
- List 파티셔닝 : 특정 컬럼값 기준으로 파티셔닝
- 대륙별, 국가별으로 파티셔닝
- Compsite 파니셔닝 : 파티셔닝의 서브 파티셔닝
- Hash 파티셔닝 : 파티셔닝 키의 Hash에 의한 파티셔닝
- 방법
- Horizontal 파티셔닝
- 장점
- 데이터의 개수를 기준으로 파티셔닝
- 데이터의 개수가 작아져서 성능 향상
- 단점
- 서버간의 연결이 많아짐
- 데이터 찾는 과정이 복잡해서 latency증가
- Vertical 파티셔닝
- 테이블의 컬럼을 기준으로 파티셔닝
- 클러스터링
- 정의
- 특정 컬럼 값을 기준으로 동일한 값을 가진 하나 이상의 테이블의 row를 같은 장소에 저장
- 데이터를 읽어오는 시간을 줄이기 위해 조인이나 자주 사용되는 테이블의 데이터를 같은 위치에 저장
- 장점
- 디스크 I/O를 줄여줌 <– row들이 모여있어서
- 모여있는 row들 사이의 조인이 발생할 경우 처리시간 단축
- 클러스터키 열을 공유하여 한번만 저장하므로 저장 영역의 사용을 줄임
- 클러스터링하지 좋은 테이블
- 조회가 자주 발생하고 수정이 거의 발생하지 않는 테이블
- 컬럼안의 많은 중복 데이터를 가지는 데이블
- 자주 Join되는 테이블
- 클러스터 Key가 되기 좋은 컬럼
- 데이터 값의 범위가 큰 컬럼
- 테이블간의 조인에 사용되는 컬럼
- 클러스터 Key가 되기 나쁜 컬럼
- 특정 데이터 값이 적은 컬럼
- 자주 데이터 수정이 발생하는 컬럼
- LONG, LONG RAW 컬럼은 포함할 수 없다
- 단일 테이블 클러스터링
- 다중 테이블 클러스터링
- 데이터베이스 백업
- 정의 : DB의 고장, 데이터의 손실 등으로 인한 피해를 최소화하기 위하여 현재의 데이터를 저장하는 활동
- 대상에 따른 분류
- 시스템 백업
- 데이터 백업
- 구성 방식에 따른 분류
- 직접 연결 백업
- 네트워크 백업
- SAN 백업
- 방식에 따른 분류
- Hot 백업 : DB 서버가 켜진 상태로 백업
- Cold 백업 : DB 서버를 중지한 후 백업
- 물리 백업 : 파일 자체를 그대로 백업
- 논리 백업 : 각 오브젝트를 SQL문 등으로 백업
- 백업 대상 파일
- data file : 데이터를 저장한 파일
- control file : 데이터베이스의 구조나 정보에 대한 상태를 저장한 바이너리 파일
- redo log file : 데이터 변경 처리 사항을 저장한 파일
- 백업 방법(MySql 사용 예)
- phpMyAdmin의 버튼 클릭만으로 콜드 백업이 가능
- Linux CLI
- Data 디렉터리 전체 복사 : 가장 빠름, 안전성과 신뢰성 문제로 권장하지 않음
- 오픈소스나 외부 백업 사용 : InnoDB Hot Backup, xtraback 등
- mysqlhotcopy :
- Mysqldump : 핫 백업 방식 지원, 논리 백업 방식 사용, 무난하게 사용
- 테이블 저장 사이징
- 사전 정보
- 각 row의 데이터 길이 계산
- 항목별 크기 계산
- 테이블 크기 산정 : 외울 필요는 없음
- 한 row 저장에 필요한 공간 = row direcotry + row header + row 길이
- 한 블록의 데이터 공간 = (Block Size – Block Heder – ITL공간) * (100 – PCTFREE) / 100
- 한 블록에 들어갈 수 있는 Row 수 = 블록 데이터 공간 / 한 row 저장에 필요한 공간
- 데이터 지역화(Locality)
- 개념
- 저장 데이터를 효율적으로 이용할 수 있도록 저장하는 방법
- 데이터 지역화를 고려한 보조기억장치 설계가 중요
- 보조기억장치의 역할
- 각 파일은 고정된 크기의 블록으로 나누어져 저장
- 데이터베이스를 장기간 보관하는 주된 장치
- 디스크상에서 파일의 레코드 배치
- 데이터를 읽고 쓰기 적합한 형태로 저장
- BLOB 타입
- 채우기 인수 : 각 블록에 레코드를 채우는 공간의 비율
- 한 블록에 레코드를 추가할 빈 공강 남김
- 고정길이 레코드 : 위치 계산이 쉬움
- 파일 조직의 유형
- 히프 파일(heap file)
- 순차 파일(sequential file)
- 인덱스된 순차 파일(indexed sequential file)
- 직접 파일(hash file)
- 물리 데이터베이스 모델링
- 데이터베이스 무결성의 종류
- 개체 무결성
- 기본키는 반드시 값을 가짐
- 기본키는 유일성을 보장하는 최소한의 집합
- 참조 무결성:
- 외래키 속성은 참조할 수 없는 값을 지닐 수 없음
- 외래키에 저장된 값은 참조된 릴레이션의 기본키 또는 NULL
- 속성 무결성 : 컬럼은 지정된 데이터 형식으르 반드시 만족하는 값만 포함됨
- 키 무결성 : 한 릴레이션에 같은 키 값을 가진 튜플들은 허용 안됨
- 사용자 정의 무결성 : 모든 데이터는 업무 규칙을 준수해야 함
- 도메인 무결성 : 특정 속성 값은 미리 정의된 도메인 범위에 속해야 함
- 무결성 보장 방법
- 응용프로그램 : 무결성 검증 코드 추가
- 장점
- 복잡한 요건 구현 가능
- 단점
- 분산되어 관리 어려움
- 개별적 관리로 적정성 검토 어려움
- 트리거 : 무결성 검증 트리거 실행
- 장점
- 통합관리 가능
- 복잡한 요건 구현 가능
- 단점
- 운영중 변경이 어려움
- 제약조건 : 데이터베이스 제약조건 기능을 선언하여 무결성 유지
- 장점
- 통합관리 가능
- 간단한 선언으로 구현가능
- 변경이 용이함
- 원칙적으로 오류데이터 발생 억제
- 단점
- 복잡한 제약 조건 구현 불가
- 예외적인 처리가 불가능
- 컬럼 속성
- 속성의 유형
- 기본 속성 : 해당 엔티티가 원래 가지고 있는 속성
- 설계 속성 : 실제 업무에는 존재하지 않지만 효율성을 위해 임의로 추가되는 속성
- 파생(추출) 속성 : 다른 속성으로부터 계산이나 변형되어 생성되는 속성
- 속성 정의시 고려사항
- 엔티티가 관리할 특성인가?
- 의미적으로 독립적인 최소 단위인가?
- 하나의 값만을 가지고 있는가?
- 원본인가 파생된 값인가?
- 키 종류
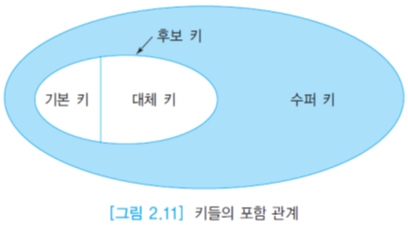
- 수퍼키(Super Key)
- 후보키(Candidate Key)
- 대체키(Alternate Key)
- 기본키(Primary Key)
- 외래키(Foreign Key)
- 데이터베이스 정규화
- 정의 : 데이터의 중복성을 제거하여 여러 엔티티의
- 정규화의 원칙
- 무손실 표현 : 같은 의미의 정보를 유지하면서 더 바람직한 구조를 만듬
- 자료의 중복성 감소 : 중복되는 정보는 삭제하거나 통합
- 분리의 원칙 : 독립적인 관계는 별개의 릴레이션으로 표현하고 각각을 독립적으로 조작
- 제1정규형 : 릴레이션의 모든 속성값이 원자값을 가지는 릴레이션(원자값이 아닌 도메인 분해)
- 제2정규형 : 기본키가 아닌 속성이 기본키에 완전 함수 종속(부분 함수 종속 제거)
- 제3정규형 : 기본키가 아닌 속성이 기본키에 비이행적으로 종속(이행 함수 종속 제거)
- 이행적 종속 : A->B, B->C이면 A->C이다
- BCNF : 함수 종속성 X->Y가 성립할 때 모든 결정자 X가 후보키(결정자가 후보키가 아닌 함수 종속 제거)
- 제4정규형 : (다치 종속을 제거)
- 제5정규형 : (후보키를 통하지 않는 조인 종속(Join Dependency)를 제거)
- 반정규화
- 정의 : 정규화된 엔티티, 속성, 관계를 시스템의 성능 향상, 개발과 운영을 단순화하기 위해 데이터 모델을 통합하는 프로세스
- 반정규화 방법
- 테이블 반정규화
- 테이블 병합 : 조인되는 경우가 많으면 테이블을 합치는 것이 성능에 유리
- 테이블 분할 : 특정 속성들만 집중적으로 접근시 테이블 분할
- 테이블 추가
- 중복테이블 추가
- 통계테이블 추가
- 이력테이블 추가
- 부분테이블 추가
- 컬럼 반정규화
- 중복컬럼 추가
- 파생컬럼 추가
- 이력 테이블 컬럼 추가
- PK에 의한 컬럼 추가
- 응용시트메 오동작을 위한 컬럼 추가
- 관계 반정규화
- 여러 경로를 거쳐 조인 가능한 경우 성능저하를 예방하기 위해 중복 관계를 추가
- 테이블과 컬럼 반정규화는 무결성에 영향을 끼칠 수 있음
- 관계 반정규화는 데이터 무결성을 깨뜨릴 위험이 없이 성능 향상에 도움
- 물리 데이터 모델 품질 검토
error: Content is protected !!